摘要
本文为系列博客tensorflow模型部署系列的一部分,用于实现通用模型的部署。通用主要体现在通过tensorboard图从已保存的模型中还原并查看模型详细结构,以及自定义模型的输入输出tensor。相关源码见链接
引言
本文为系列博客tensorflow模型部署系列的一部分,用于python语言实现通用模型的部署。通用主要体现在通过tensorboard图从已保存的模型中还原并查看模型详细结构,以及自定义模型的输入输出tensor。本文主要使用keras和pb两种模型文件,其它格式的模型文件请先进行格式转换tensorflow模型部署系列————预训练模型导出
主题
上一篇博文tensorflow模型部署系列————预训练模型导出就如何将模型导出为文件以及如何利用模型文件进行推理进行讲解,博文中也开放了使用python进行模型推理的代码,本文也是使用python进行模型推理。主要区别在于:
- 将模型推理代码对象化,分离模型加载和模型推理为不同的方法,以减少实际部署时速度过慢问题
- 有时我们拿到的只有模型文件,如网上下载、比赛提交代码、前同事留下的模型等等。我们并不知道这些模型文件的具体结构及内部张量名称,使得模型部署无法进行。本文会介绍查看模型文件模型结构及张量名称的通用方法,进行可以对任意模型文件进行部署
查看已保存模型的结构
keras模型文件
-
打印模型结构
model.summary() -
绘制简单的模型图
keras.utils.plot_model(model,'./keras/model.png') -
生成tensorboard文件
tensorboard_callback = keras.callbacks.TensorBoard('./keras') tensorboard_callback.set_model(model) tensorboard_callback.writer.flush()
pb模型文件
-
生成tensorboard文件
file_writer = tf.summary.FileWriter('./pb') file_writer.add_graph(graph) file_writer.flush()
然后输入命令行tensorboard --logdir=./查看tensorboard模型图
查看已保存模型的输入和输出
通过tensorboard图查看
在网页中点击图的输入和输入即可看到输入和输出的详细属性。注意:如果输出是矩形框,说明它是组合操作,要双击进入到它的内部,找到最后的椭圆形才是模型可识别的tensor

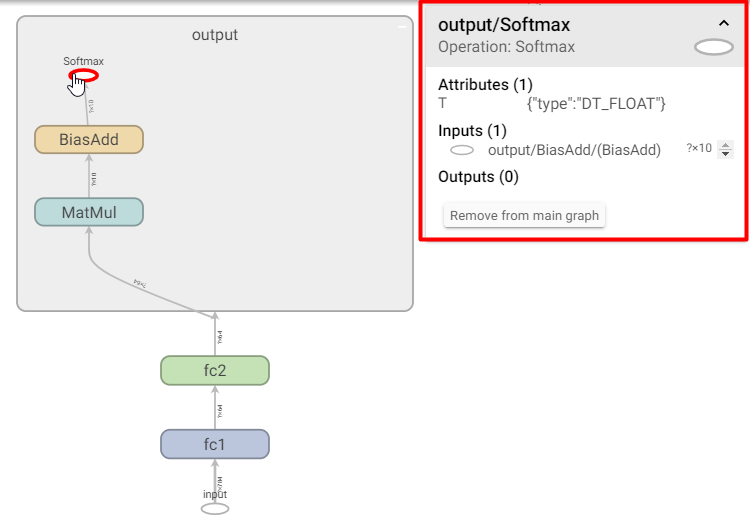
最终代码要在tensor名后加上:0上图中输入tensor名称为input:0,输出tensor名称为output/Softmax:0
通过代码查看
通过代码查看所有op名称
op = graph.get_operations()
for i, m in enumerate(op):
print('op{}:'.format(i), m.values())
以上代码会打印出很多图,如下格式
op0: (<tf.Tensor 'sequential_1_input:0' shape=(?, 784) dtype=float32>,)
op1: (<tf.Tensor 'fc1/random_uniform/shape:0' shape=(2,) dtype=int32>,)
op2: (<tf.Tensor 'fc1/random_uniform/min:0' shape=() dtype=float32>,)
op3: (<tf.Tensor 'fc1/random_uniform/max:0' shape=() dtype=float32>,)
.
.
.
op的打印顺序大致以 以下顺序排列:
- 前向传播op
- 占位符op
- 优化器op
- 评估指标(loss、acc)op
- 反向传播梯度op
我们查找输入输出op时只要在前向传播op里面寻找就行了。一般来说,打印的第一个op是输入op,前向传播op的最后一个op为输出op。当然,我们也可以根据需要用中间一些op做为输入和输出,这在提取特征和迁移学习场景会用到
以第一行为例。'sequential_1_input:0'为张量名称,float32为张量类型,(?, 784)为张量维度
python部署代码
模型封装类
模型封装类主要包括两个方法:初始化和推理。
初始化只用于处理与sess.run无关的所有操作,以减少推理时的操作,保证模型推理高效运行。初始化主要进行的操作包括:模型文件加载、获取计算图和计算session、根据输入输出tensor名称获取输入输出tensor
推理仅仅执行sesson.run操作
模型封装类示例代码
经过模型封装类封装以后,示例代码就很简单了。只用准备数据,然后推理就行了。
示例代码
-
模型文件分析
-
python部署