摘要
本文将低级api实现的tensorflow网络移植到高级api上遇到的loss值不变和训练结果不收敛问题
引言
tensorflow版本更新很快,猛一回头发现已经推出更高级的api了
主题
tensorflow高级api
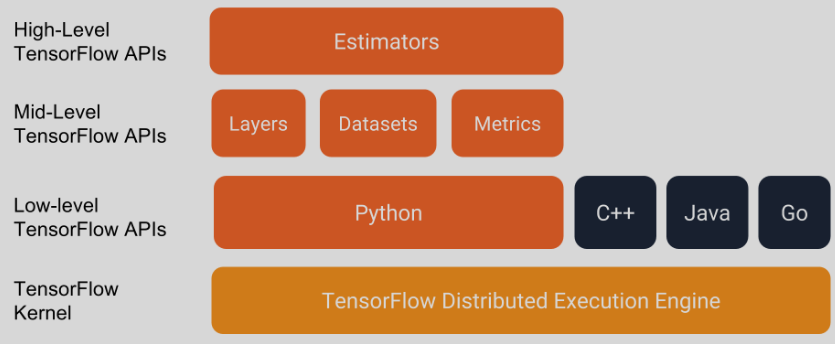
上图是tensorflow软件栈图,我之前学习和实现的网络模型(0.12a)使用的是 低级api, 现在的新版本(1.10)对低级api进行了封装,形成了高级api(estimator keras),所以对原有模型进行了一次api替换
移植
整个代码的移植过程还是比较顺利的,移植完成以后,代码量比以前减少了很多,但移植完成,在运行时却发现了一些奇怪的现象
问题现象
我这里有两个自己的数据集,其中一个数据集(单个数据量130)在移植后的代码上运行正常,另一个数据集(单个数据集60000)在移植后的代码上运行却出现以下问题:
- 二分类问题的准确率在50%左右
- 训练过程中loss值会变化到一个固定值,然后就不再变化了
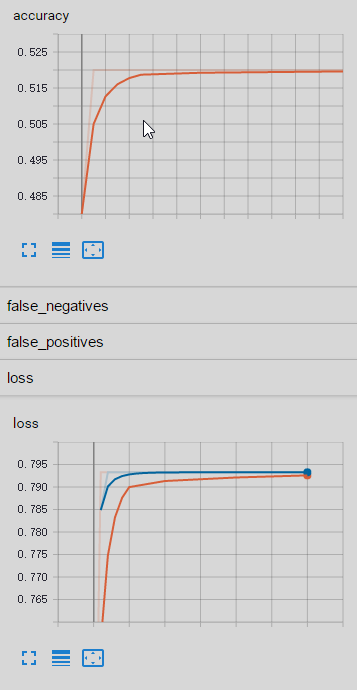
epoch:0
Evaluation results: {'true_negatives': 48.0, 'global_step': 0, 'loss': 0.7953733, 'true_positives': 0.0, 'accuracy': 0.48, 'false_negatives': 52.0, 'false_positives': 0.0}
epoch:1
Evaluation results: {'true_negatives': 0.0, 'global_step': 1, 'loss': 0.79326165, 'true_positives': 52.0, 'accuracy': 0.52, 'false_negatives': 0.0, 'false_positives': 48.0}
epoch:2
Evaluation results: {'true_negatives': 0.0, 'global_step': 2, 'loss': 0.79326165, 'true_positives': 52.0, 'accuracy': 0.52, 'false_negatives': 0.0, 'false_positives': 48.0}
epoch:3
Evaluation results: {'true_negatives': 0.0, 'global_step': 3, 'loss': 0.79326165, 'true_positives': 52.0, 'accuracy': 0.52, 'false_negatives': 0.0, 'false_positives': 48.0}
epoch:4
Evaluation results: {'true_negatives': 0.0, 'global_step': 4, 'loss': 0.79326165, 'true_positives': 52.0, 'accuracy': 0.52, 'false_negatives': 0.0, 'false_positives': 48.0}
epoch:5
Evaluation results: {'true_negatives': 0.0, 'global_step': 5, 'loss': 0.79326165, 'true_positives': 52.0, 'accuracy': 0.52, 'false_negatives': 0.0, 'false_positives': 48.0}
问题分析
因为不同数据集对应的结论不同,所以问题的排查就主要集中在对比两份代码的差异上了。训练正常的代码简称为T代码,训练异常的代码简称为F代码
- 网络排查
怀疑模型代码有问题。将F代码尽量用T代码代替,最终替换后,只剩下tfrecord文件读取和解析、网络输入层不一样,然后再训练更新后的F代码,现象依然存在
- 数据排查
通过网络排查基本排除网络问题,唯一不同在于数据,于是进行数据验证。将F代码训练过程中的输入数据记录到文件,然后对比F代码读到的数据和制作tfrecord的数据。排查数据编号、数据内容是否一致。最终发现数据一致。 ``` class _LoggerHook(tf.train.SessionRunHook): “"”Logs loss and runtime.”””
def begin(self): # print(‘begin’) self._step = -1
def before_run(self, run_context): # print(‘before_run’) self._step += 1 return tf.train.SessionRunArgs(features) # Asks for loss value.
def after_run(self, run_context, run_values): if self._step == 2: logit_value = run_values.results print(‘step ‘ + str(self._step) + ‘, features = ‘ + str(logit_value)) f1.write(logit_value[‘data’]) # 训练准确率写入文件 f1.flush() numpy.savetxt(r”/home/zq537/ckpt/ecg_data.txt”, logit_value[‘data’]) numpy.savetxt(r”/home/zq537/ckpt/index.txt”, logit_value[‘name’]) ```
- 内部训练过程排查
如果网络和数据都没问题,那么问题排查起来就比较困难了。接下来的方向可能需要深入模型内部的训练过程,看哪些步骤导致loss和准确率不变,将所有操作的输出和反向传播的梯度都记录到tensorboard中进行查看,发现进行少量的训练后,反向传播的梯度值分布都在0附近,这样网络权重基本就不会更新了,网络参数没有变化,自然准确率和loss也不会变化了。
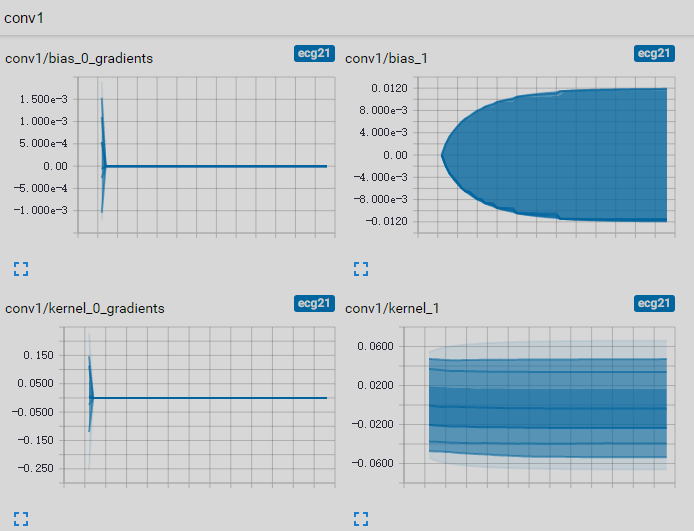 是什么原因导致梯度为0?梯度是从loss开始,一层一层往前传的;而loss是由预测值和实际标签共同决定的。于是我开始查看预测值和实际标签的数值。先把数据集进行简化,生成10个数据的数据集,batch-size设为10,然后在训练回调中把稳定(loss不变)时的预测值和实际标签打印出来,发现了问题:稳定状态下预测值大部分两分类的准确率都是1,这很明显是给网络的评判标准(loss函数)有问题
```
labels = [[1 0]
[1 0]
[0 1]
[1 0]
[1 0]
[0 1]
[0 1]
[0 1]
[0 1]
[0 1]]
是什么原因导致梯度为0?梯度是从loss开始,一层一层往前传的;而loss是由预测值和实际标签共同决定的。于是我开始查看预测值和实际标签的数值。先把数据集进行简化,生成10个数据的数据集,batch-size设为10,然后在训练回调中把稳定(loss不变)时的预测值和实际标签打印出来,发现了问题:稳定状态下预测值大部分两分类的准确率都是1,这很明显是给网络的评判标准(loss函数)有问题
```
labels = [[1 0]
[1 0]
[0 1]
[1 0]
[1 0]
[0 1]
[0 1]
[0 1]
[0 1]
[0 1]]logits = [[1.0000000e+00 1.0000000e+00] [1.0000000e+00 1.0000000e+00] [1.0000000e+00 1.0000000e+00] [1.0000000e+00 1.4896728e-36] [1.0000000e+00 5.1295980e-18] [1.0000000e+00 1.0000000e+00] [1.0000000e+00 1.0000000e+00] [1.0000000e+00 1.0000000e+00] [1.0000000e+00 1.0000000e+00] [1.0000000e+00 1.0000000e+00]] ```
新代码中使用的损失函数是
tf.losses.softmax_cross_entropy(onehot_labels=labels, logits=logits),搜索并替换为tensorflow官方module库中的损失函数tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)再进行训练,发现一切正常
问题原因
- 网络排查
- 数据排查
- 内部训练过程排查
解决方案
总结
- 在pypi官网上找相关模块信息
最开始在网上搜到的方案是ConcurrentLogHandler,但在13年就停止维护了, 合入代码也无法运行。于是又在网上找其他方案(这里浪费了不少时间),其实 ConcurrentLogHandler的homepage页已经说明了替代的库